Our development team is constantly improving the RUDDER software. They have to be at the cutting edge of technology. This blog shares tips and technical feedback directly from the developers.
How to apply different value to my configuration data variable? For example, changing virtual IP address depending on the cluster?
When using configuration management for your IT, you have to deal with a lot of variables as placeholder for your configuration data. From passwords to IP, from OS specific path to server current properties, they are not all alike in kind, in life cycle, or even in who knows what their value should be. Some of them can only be known on the node (I will use ‘node’ to indistinctly talk about server, desktop, container, embedded device, etc), and others can be known beforehand.
In Rudder, we try to address these different kinds of variables each with their specificities. This article presents how we deal with the latter ones – the ones which are part of your general IT architecture, and specifically how you can organize them to keep bloating low, manage all kinds of exceptions, and still have a precise understanding of the value of each variable, debuggable if needed.
TL;DR
In that article, we explain how these data need to be stored along with configuration logic to avoid dreadful unsync between them. We also present how we allow Rudder’s users to organize data that depicts IT operations knowledge in hierarchical categories, which is generally how we, humans, think about such knowledge. Rudder also provides value overrides to allow refinement from the general case to the most specific ones.
We choose to map hierarchies to Rudder node groups and subgroups since it’s already the best categorization that ops thought about regarding their nodes in Rudder. And since we need to always be able to decide what override has a higher priority than another but limit the tediousness of the task of declaring such priorities for all cases, we fall back on graph theory to use a well defined sorting algorithm, topological sort, to let the user specify only the important priority – the one linked to their expertise, and let the computer handle the tediousness.
Benefits are an overriding logic following a principle of least surprise based on sound theory without edge cases, even for nodes which belong to several hierarchies with overlapping properties, clear error messages when some priority rules are missing, and a nice linear representation of property inheritance that is easy to display in UI and inspect for debugging.
IT ops knowledge
What we call “IT ops knowledge” is all these properties that need to be used by your operation team for configuration and that can be specified based on constraints independent of the environment state when the configuration happens, like infrastructure architecture (topology, hardware and software stacks), business or security constraints, best practices and hard earned experience.
Typically, you encounter that kind variable to store question/answer pair along the way of:
- “What is the DNS on that datacenter?” “1.1.1.1 except for that one client who expressly asked for 8.8.8.8”
- “What is the path to that configuration file?” “It depends on OS and version”.
- …
Conceptually, these properties are a variables, i.e. a name, used as an identifier, referenced in configuration code in place of the value that needs to be abstracted away, and a value, typically a semi-structured format like JSON that depends on which node the configuration will be done.
Usually, these variables deal with things that should be common and factored out, that are set by constraints external to the configuration logic, and for which, most likely, there is no good answer that can be guessed from a code point of view.
For example, your organization chose to normalize ssh connections to print an MOTD on login depending on who the customer is: the logic to print a message is always the same, but that message is pure configuration data.
Another example is a variable whose value depends on a statically known property of the IT environment: typically, all your managed node can follow the same network configuration logic, but the actual value of a DNS or gateway may depend on which datacenter it is installed in, or privacy/security levels ; JVM memory size is always configured the same way for all JAVA application you manage, but the actual value will depend on the sizing of said app. Etc.
Categories, exceptions, and overriding
Quickly, that knowledge grows out of control and you yearn to categorize properties: “all the properties for nodes in datacenter EU-42”; “properties for CentOS based nodes”. And soon, you need overriding, because you have common properties for all CentOS, and a subset is different for CentOS 8, so you would like to just redefine these ones. It would be a real pain to have to define only exclusive sets. Imagine having: “properties common to really all CentOS”, “properties for CentOS 6 and 7, but not 8”, “properties for CentOS 6 and 8”, and so on – especially since before you blink, you get exceptions everywhere: “properties just for CentOS 8.1-1911, because they behave differently”. You think it would be a nightmare, but you don’t even have half of complexity: your categorization must be resilient to changes. With new properties to add or old to remove, defining those sets would be an error prone set-up with apocalypse following shortly afterward.
The classical answer to that problem is to be able to define value override between categories. With override, you can keep your categories defined by topic even if some topic partially overlaps with other categories. You keep your definition simple and self-consistent, and prioritization becomes an orthogonal problem.
To keep surprise low (that’s an ever good property in IT), we will also force properties of a same category to always have the same behavior regarding overriding.
Override, total order and decidability
An override is the possibility to redefine (part of) a value of a variable (the overridden one) with another value (the overriding one). Algorithm may differ in details, but you get the general idea with the following example of the case of a string or a json-like structure:
It’s the perfect fit to be able to describe exceptions in general cases without having too much bloating involved.
The hard part is to be able to get the “overridden / overriding” relationship in a reliable way, which means to be able to order all the places where a variable is defined. But you need to make sure that the order is defined 1/ for all pairs, 2/ in a consistent fashion.
1/ is necessary because without that, you could have a property that is defined at two different places without an order between them. At best, you could take an order at random, but you really don’t want to rely on luck to manage your IT. The property of having the order relationship defined for any two pairs is called “connexity”.
2/ in a consistent fashion essentially means that your relationship is transitive, i.e that if you define somewhere that a is overridden by b, and elsewhere that b is overridden by c, then you want to have a overridden by c.
A third property for reliability is that you can only say “a is overridden by b and b is overridden by a” when a equals b.
These three properties are defined for a total order, and so it’s what we need on our variables to not break our configurations.
The human factor against tediousness
From a technical point of view, it’s trivial: for a given property identified by its name, sort all of its definition sites from the one with the lowest priority to the one with the highest. Then, at each stage, apply overriding rules on the last value with the new one. Done!
Technically sound. But you still have to prioritize all categories relatively to each other – and you need to do it again each time a variable is added in two or more categories.
It is not good at all. First, because it would be maddening and of very little perceived value: soundness can’t be traded off if you don’t want to break your system in creative and surprising ways, but if it’s too tedious, most human will just prefer to not use the system at all, or find easy and wrong way to workaround it.
But secondly, and perhaps more importantly, because forcing someone to define all these category relationships would totally hide the logic behind your sorting, the important business decision behind the ones that are just natural translation of physical properties of your IT infrastructure.
Wait, isn’t that just a CMDB ?
A CMDB, or other central configuration data management tool, is by definition a central point of configuration data *independent* of configuration logic. It’s “just” a complex base for data, with a tailored lifecycle, ACL, encryption and transfer channel, and millions of other transversal properties. It is a necessary piece of knowledge in an organization, but it is not a node-centric view, and it is not versioned along node configuration data – actually, it must not, to fulfil its role of reference point.
But IT ops knowledge properties are most of the time extremely tightly bound to configuration logic – or in the opposite way, configuration logic must be adapted to change with these properties. Both need to co-evolve together or your configurations will break in subtle, apocalyptic ways. What do you think will happen if you change the authentication method to access one of your SaaS tools before the corresponding logic is implemented? And yet, this is a clean, easy to spot error. More perversely, what happens when you revert your configuration logic to a previous version if configuration data are not restored along the way? If it almost works?
Hierarchies of properties
So coming back to how to define priority in our categories and trying to address the two pain points we saw, we can remember that we are not solving an abstract problem: we want to sort categories of nodes – ie servers, desktops, etc.. Since we deal with nodes, extremely often, the categories we define depict an “is a” (or “belong to”) relationship with the node. “That node is a CentOS 8.1”. “That node belongs to DataCenter 42”.
And for most of these categories, the sorting is self-explanatory, because what we really deal with are hierarchies translated from physical properties:
- “That node is a CentOS 8.1. Which is also a CentOS 8. Which is also a CentOS. Which is also a Linux”.
- “That node is in datacenter 42. In France. In Europe”.
Moreover, most of the time, these hierarchies are the common language of IT operation, i.e. they are the natural way operations talk about their nodes. It would be inefficient and surprising (i.e: very bad) to not use the business language of the domain to talk about its entities.
Hierarchies are also a well known human tool, easily understandable, and in the case of mono-branch hierarchies, extremely simple to order. In that case, defining override priority is trivial: the most general case is the one with the lowest priority, used to define default values, especially for properties that must be defined in all cases. The values are refined following the hierarchy line, down to the node itself which holds all exceptions that are too specific to be defined anywhere upward.
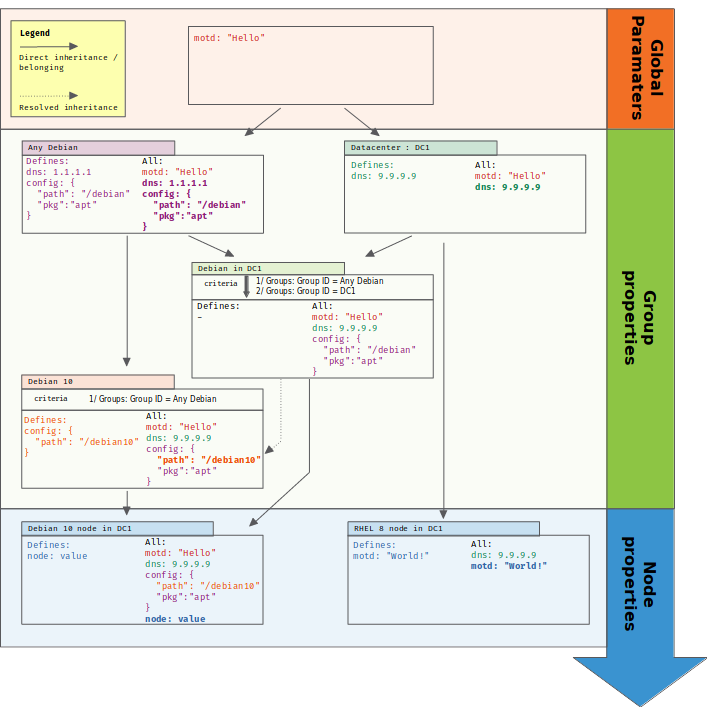
In the following example, we have a category defined for all Debian nodes. Then, a subcategory is defined for Debian 10 nodes, and only overrides some property from its parent category. A Debian 10 node will get the correct set of refined values, and can even define its own ones.
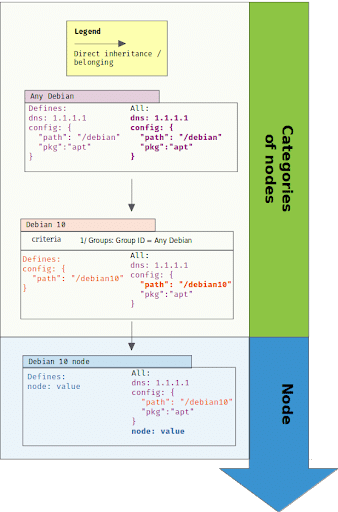
Nodes in several hierarchies
As you may see, we will have a problem for properties belonging to several hierarchies. Hierarchies only define a total order if they don’t have any branches. As soon as your hierarchy is a tree, branches are not ordered one related to the other. In that case, if a variable is defined in each branch, value is undecidable.
In the following case, we added a new category of nodes based on the node location (in datacenter 1). That category also defines variable “dns”. So, what value should get a Debian 10 node in datacenter 1 ?
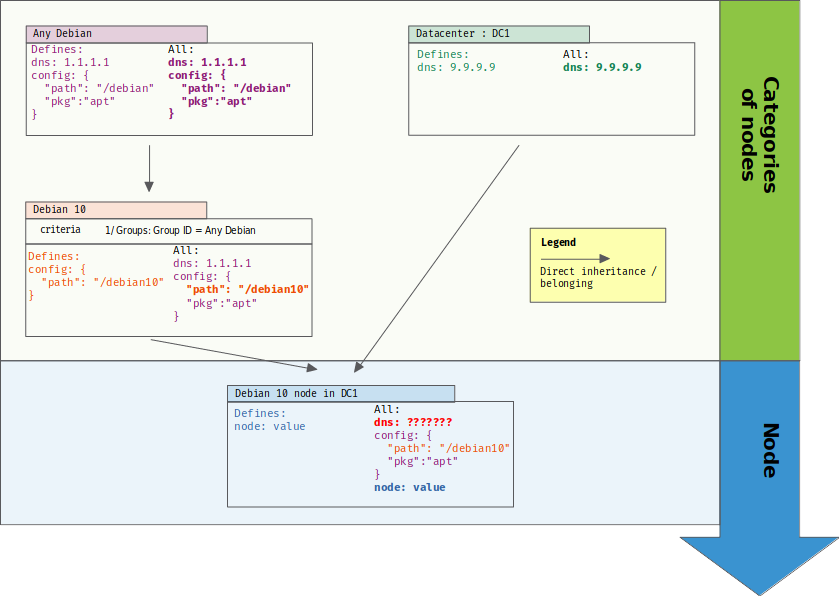
From hierarchies to graph and total order
So, we just have to transform our tree of hierarchies back into a hierarchy with only one branch:
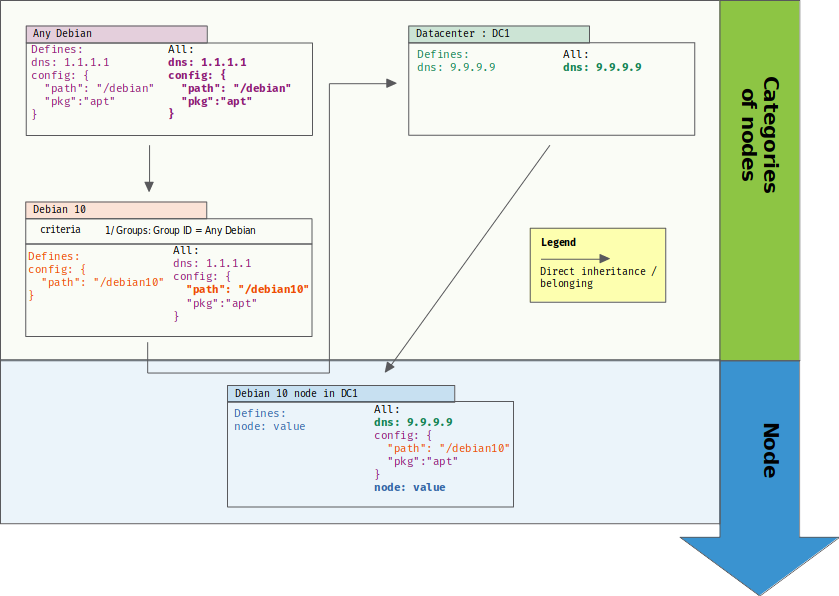
Of course, if you are forced to do that, you lose separation between definition and prioritization: both are linked again, and you get back the maintenance nightmare that we tried to avoid: defining all categories in only one axe.
Fortunately, graph theory comes to the rescue. We know how to sort a direct acyclic graph (DAG) in all cases with its topological sorting. And a tree is a couple vertice away from a DAG: by adding a directed edge between “Debian 10” category and “DC1” one, we can teach our categorization to resolve overriding in a sound way:
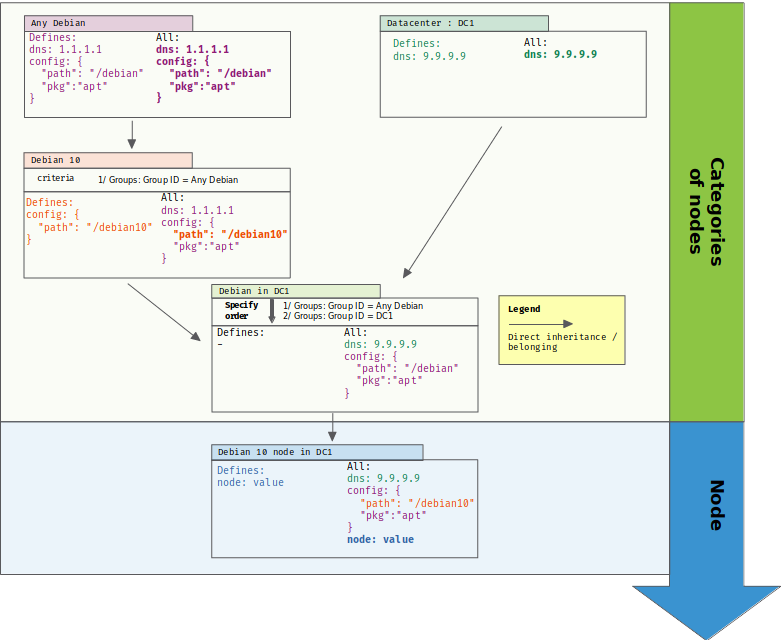
Now, two things are even better with that solution:
- the added edge represents a business choice, it’s the materialization of IT ops knowledge: “in our company, we chose that DNS is firstly defined by datacenter, and in the case when the datacenter category doesn’t define that property, then we fall back to a general case from one other category”
- we don’t even need to define the edge at the convergent point of branches: it can be defined between any two categories in each branch, and it provides an ordering for all categories below it. It means that we only need ONE edge to define the business choice that “datacenter” category is alway more prioritary than “Debian” – or any of its children – for overriding.
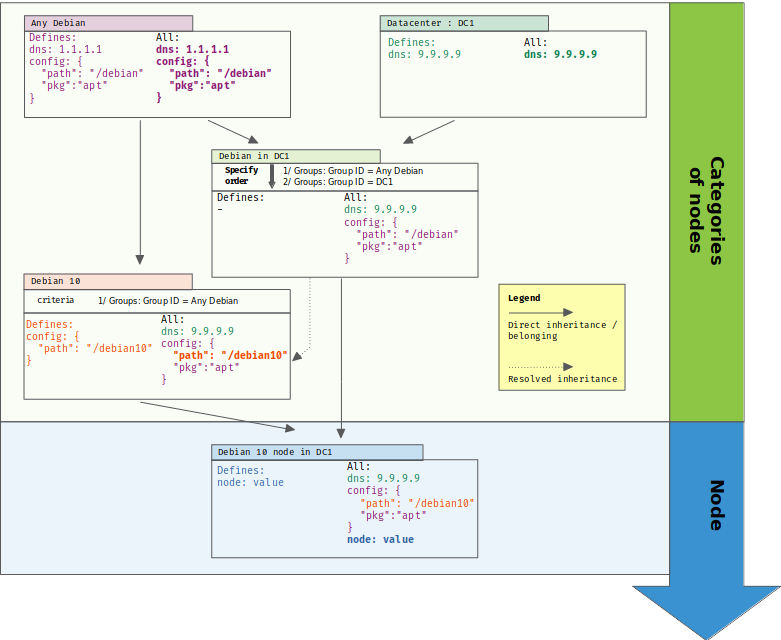
Rudder solution
Rudder provides all the above and we tried very hard to make it as seamless as possible to use for the user so that said user will actually find it useful to have a sound system:
- Rudder encourages users to define dynamic groups of nodes to define configuration. Their composition automatically follows the moving reality of IT infrastructure. These groups can be linked by subgroup relationships, and so they are a natural way to define node category hierarchies in Rudder.
- Rudder allows you to define general cases in “Global Parameters”, which are properties that are inherited by all categories and nodes.
- Rudder checks for you when the partial order provided by hierarchies is not enough and asks you to specify a group ordering just for these cases, which are most likely important business decisions that need to be materialized. It minimizes information bloat and keeps the soundness of the system.
- At any level in the hierarchy, Rudder provides a view of the linearization of the overrides that lead to a variable value. If it doesn’t match your expectation, it is easy to spot what group defines the bad value.
For a practical, step-by-step use case, you can look at the rudder by example “Using group properties for hierarchical variable and manage overriding conflict” article that explains how to implement in Rudder the following IT ops knowledge use case: